The Basics of Language Modeling with Transformers: Switch Transformer
Introduction
Switch Transformers introduced by researchers from Google appears to be the largest language model to be trained till date. Compared to the other large models like Open AI’s GPT-3, which has 175 Billion parameters, and Google’s T5-XXL, which has 13 Billion parameters, the largest Switch Model, Switch-C, has a whopping 1.571 Trillion parameters! This model was trained on the 807GB “Colossal Clean Crawled Corpus”(C4). Their efforts to increase model size are based on research that suggests models with simpler architectures but more parameters, data and computational budget perform better than more complicated models.
From Mixture of Experts (MoE) to the Switching Layer
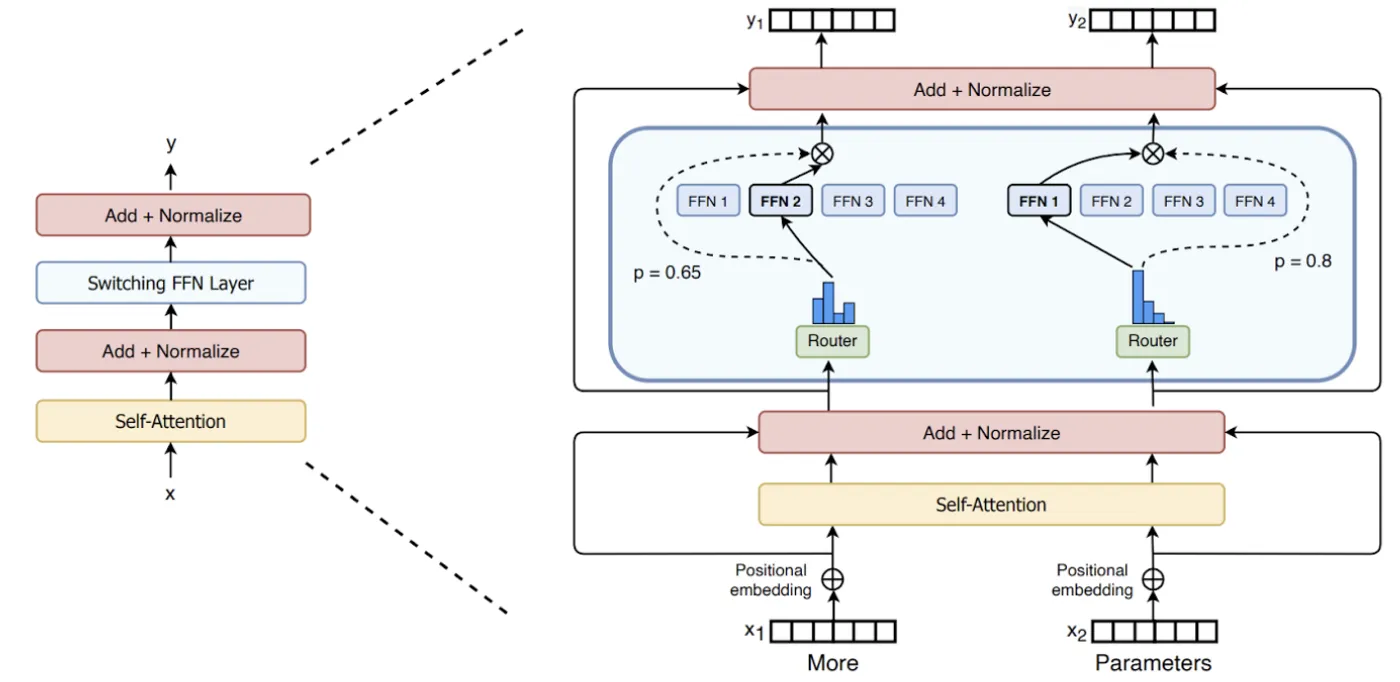
The switch transformer was able to achieve this parameter scale by using Mixture of Expert (MoE) models. Unlike traditional deep learning models, which use the same parameters for all inputs, MoE models use different parameters for each input. This results in a sparsely activated model, which can have many more parameters while maintaining the same computational budget as a model with parameters equal to those that are activated at any given time. For instance, a dense feed forward layer with N nodes can be transformed into a sparse MoE layer by having K dense feed forward layers with N nodes each and a trainable routing function to direct the input to one or more of them. The routing function is a vector of size N, Wᵣ, with trainable parameters which when multiplied with the input x, and normalized via softmax, produces a probability distribution over the N expert layers. For each expert i, we get pᵢ(x) = softmax(Wᵣ x)ᵢ.The output, y, of the MoE layer is the weighted sum of the outputs of the top-k experts. Concretely, if T is the set of top-k indices, and output from expert i ∈ T is Eᵢ(x), then y = ∑ᵢpᵢ(x)Eᵢ(x).
Creators of the switch transformer, Fedus, Zoph, et al., went against prevailing views by using only one expert (k=1) at each MoE routing layer to create the eponymous layer of the Switch Transformer. Earlier, researchers had intuited that at least two or more experts would be needed to learn how to route, and others reported that in models with many routing layers higher values of k in top-k routing were needed in layers closer to the input. However, the creators of the switch transformer go on to show that the switch-transformer can perform well on many NLU tasks, while saving computation and communication cost.
Using Model, Data, and Expert Parallelism

The switch transformer is able to scale up well because they are able to minimize communication requirements by using model, data, and expert parallelism. Their Switch-C model (1.5T parameters), uses data and expert parallelism, whereas the Switch-XXL (397B parameters), uses data, model, and expert parallelism.
Expert parallelism implies that weights of each expert lie in a different core. Thus when a batch B of inputs of size T reaches the router function, it must route each input to the right expert. To fix the maximum computation on any one expert, the maximum number of input tokens routed to each are also fixed. This number is called ‘expert capacity’. Expert capacity is the batch size of batch size of each expert calculated as (T/N) * capacity factor. If more tokens are routed to an expert than it’s capacity, i.e. when tokens overflow, they are passed onto the next layer through a residual connection. Scaling expert capacity using the capacity factor (a hyper parameter) helps mitigate token overflow.

Reducing Communication cost with Selective Precision

Another interesting problem solved by the authors of this work is using low precision numbers, such as ‘bfloat16’. ‘bfloat16’ is Google Brain’s 16 bit float precision format (b for brain) created by truncating float32 to the first 16 bits. In prior MoE works, using bfloat16 precision caused instability during training and forced the use of float32 precision. The creators of the switch transformer circumvented this issue by using high precision numbers only in the router computation, which is local to a given core, and showed that training still converges. This reduced the communication cost between cores by two, and increased throughput (speed).
Performance of the Switch Transformer
Fine Tuning Results
Switch models show performance improvement in all but one downstream fine tuning task: the AI2 Reasoning Challenge (ARC). Overall they saw gains with increasing model size, and also gains in both knowledge heavy and reasoning tasks, when compared to their FLOP matched baselines.


Scaling Properties
Scaling on the basis of training steps
The authors found that more experts achieve lower loss and higher performance for a fixed number of steps, when the amount of computation (FLOPs) per token is held constant (left figure below). This means that sparser models learn faster in terms of number of training steps. Their switch-base 64 model achieved a 7.5x speed up in terms of step time compared to the T5-base model (not shown in the figure below). The plot on the right implies that larger models are more sample efficient, i.e, learn faster for a fixed number of observed samples.

Scaling on the basis of training time
The authors wished to understand that for a fixed training duration and computational budget, should one train a dense or a sparse model?
First, they noted that their sparse models outperformed the dense baselines: the model with 64 experts achieves a given loss 7x faster than T5-Base.

Diving deeper into time to train of the largest models, we see that the Switch-C model gets to a fixed perplexity (-1.096) four times faster than T5-XXL, while maintaing the same computational budget. Note the multiplier is four and not two because the reported value is in the logarithmic domain.

Conclusion
In this article I introduce what appears to be the largest language model trained to date: Google's Switch Transformer. Switch-C has 1.5 Trillion parameters and Switch-XXL has 395B parameters. These models are able to be trained in an efficient manner because they are sparsely activated, which means only a fraction of of the model parameters are used while performing inference for a given input. I discuss how the switch layer and token routing works, the main innovations and experiments related to efficient scaling, and the performance gains of these innovations. It's important to note that there are other interesting experiments and techniques mentioned in the paper such as distillation, multilingual learning, expert dropout, etc. that I haven’t discussed in this summary. The motivated reader might want to refer to the paper to read about them. Nonetheless, it's exciting to see how the NLU community is pushing the bounds on model scale while computation and communication during training and deployment are constrained.
References
Fedus, et al. (2021) “Switch Transformers: Scaling to Trillion Parameter Models using Simple and Efficient Sparsity” https://arxiv.org/pdf/2101.03961.pdf