The Basics of Language Modeling with Transformers: The Birth of the Transformer

Introduction
2017 marked the release of Michael Bay's fifth and last movie on sentient shape-shifting vehicles from outer space, but in the same year Google Brain did one better with transformers: it introduced a ground breaking neural network architecture called just that. Transformers were introduced in the seminal paper “Attention Is All You Need,” which set the stage for rapid advancements in the field of natural language understanding (NLU). In this article I will share how the state of the art natural language models that are based on transformers came to be and explain the core innovation around its architecture: the attention layer.
But before that, let us briefly touch upon the nature of the problem and the history of neural networks used in this field.
One key characteristic of all NLU tasks is that the input data is sequential in nature. A word in a sentence derives its meaning from the context from the words preceding it (left context) and those that come after it (right context). The state of the art in NLU was constrained for three decades due to this sequential nature of the inputs, especially the right context of a piece of text, and long lengths of these sequences.
The first neural networks used to model natural language were Recurrent Neural Networks (RNNs). RNNs are a form of feedforward neural networks, and work by generating a sequence of hidden states using, to compute each, both the prior hidden state and the current input. Thus, they don't capture the right context and since need to be sequential, parallelization during their training is impossible. This means they are slow to train, even when using a truncated form of back-propagation. Further, they suffer from the vanishing & exploding gradients problem during training which precludes them from predicting long sequences of text.
Long Short-Term Memory (LSTM) neural networks were introduced to address the vanishing gradient problem, and did advance the state of the art by being able to model longer sequences. They were able to do so by using specialized gates, which however meant they were more complex than RNNs, still sequential, and a result even slower to train.



Transformers
In 2017 Google Brain published a groundbreaking paper called “Attention Is All You Need,” which would set the stage for rapid advancements in the NLU state of the art. Their innovation, the Transformer, would eliminate the need for recurrence or convolution in deep learning on sequential data in their entirety. That meant inherently quicker models which could also take advantage of advancements in data parallelism and model parallelism.
At their core, transformers were made up of 4 basic elements:
- Embeddings
- Positional Encoding
- Encoder Block
- Decoder Block
Embeddings
This is basically a lookup table to map words to learned vector representations with continuous values.
Positional Encoding
In order to preserve sequence position information we must inject some information about the relative position of each word in order to capture contextual information. There are many options for how to achieve this, but the authors chooses sine (for even timesteps) & cosine (for odd timesteps) functions to embed positional information since this allows for linear representations of any given positional encoding in terms of a preceding positional encoding.
Encoder Block
The encoder’s job is to transform the input sequence into context vector representations for each unit in the sequence. Each encoder layer has a multi-head self-attention (more on this below) layer, and a simple, position-wise fully connected feed-forward network. Each sublayer uses layer normalization & residual (or skip) connections. We can stack encoder layers in order to learn more complex representations.
Decoder Block
The decoder takes in the input sequence as well as an input from the encoder, and uses multi-headed attention to determine the appropriate decoder output for a given encoder input. After the multi-headed attention layers, the data goes through a feed-forward network, as well as a linear and softmax layer to map the probability distribution to the size of the vocabulary and select the most probable word.
Attention
At the core of transformer architecture is attention. Instead of encoding a whole sequence to a fixed context vector like in traditional RNN encoders, it develops a context vector filtered for each timestep. Most notably, transformers take advantage of a self-attention mechanism. This allows the model to determine the relevance of a word given the other words in the sequence.
The input is mapped to a query, key and value, which are all vectors. Analogies have been drawn to search engines which compare your query against a set of keys (metadata) associated with rows in the database, and return the best match values (results).
Transformers take advantage of scaled dot product attention (formula below), which reduces runtime and space, by using matrix multiplication & taking advantage of optimizations for such operations on the GPU side.

Let’s break it down:
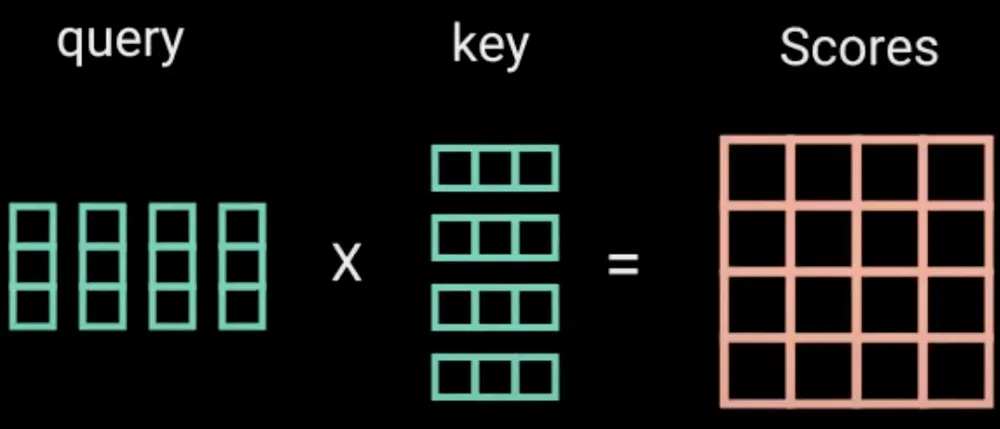
The query & key are multiplied to generate attention scores:
These are then scaled down by the square root of dimensionality to prevent holding softmax in its saturated regions and avoid vanishing gradients.
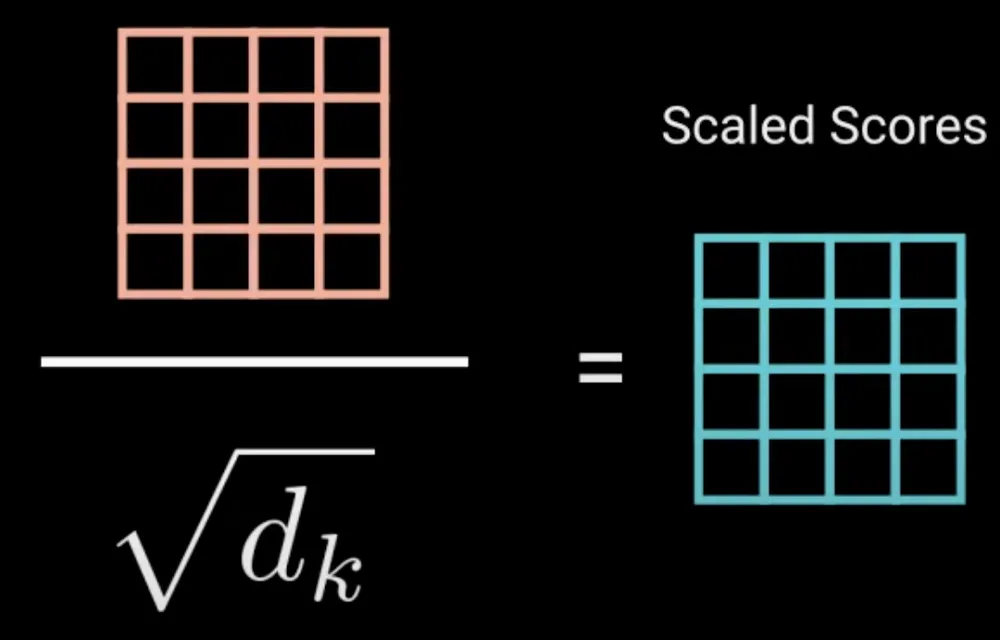
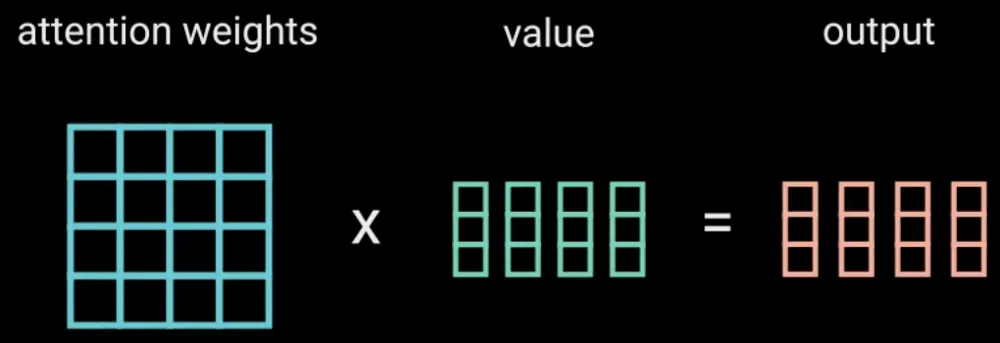
Finally, we multiply these weights with the values to produce an output layer, which is processed through a linear layer to generate a result.
Computational Complexity of Self-Attention
In terms of computational complexity, self-attention layers are faster than recurrent layers when the sequence length n is smaller than the representation dimensionality d, which is most often the case.

Performance and Training Cost of Transformers
As a direct result of this, combined with the increased amount of computation that can be parallelized by minimizing sequential operations, transformers improve on the state of the art both in terms of performance and training cost on the machine translation task called BLEU (bilingual evaluation understudy), as can be seen in the table below.
 compared to other approaches")
Conclusion
Transformers are neural architectures that do away with recurrences and convolutions and are based solely on attention. These models improved the state of the art performance on machine translation tasks and did so while radically reducing the amount of computation needed to achieve that performance. Transformers set the stage for massive jumps in performance for natural language and temporal models, and form the basis for advancements such as Open AI’s GPT models, Google’s BERT, and Google’s Switch Transformer, which I will discuss in upcoming articles.
References
- Vaswani, et al. (2017). Attention Is All You Need. arXiv:1706.03762v5.
- Key-value graphics taken from https://www.youtube.com/watch?v=4Bdc55j80l8&t=300s&ab_channel=TheA.I.Hacker-MichaelPhi
- Banner image modified from: https://www.teahub.io/viewwp/wTRTxb_transformers-wallpaper-hd/