Introduction
BERT is a product of Google AI, and a truly creative spin on transformers and the attention mechanism. Transformer models are directional, that is, they read the text input sequentially. BERT uses just the transformer encoder, along with bidirectional self-attention, which reads the entire sequence of words at once, in order to learn the context of a word based on the sequence succeeding & preceding it.
There are two BERT architectures: BERTBASE, with 110M parameters and 12 transformer blocks, and BERTLARGE with 340M parameters and 24 transformer blocks. The implementation can be broken down into two steps: pre-training and fine tuning. These two steps allow for good performance using a smaller training corpus, since the pre-training step can use unlabelled data while relying on fine-tuning using labelled data to compensate for lost information. Recall this technique was also used in OpenAI's GPT discussed in a previous article.
Unsupervised Pre-Training

Pre-training on BERT can be broken down into two tasks, and trains using a combined loss of both:
- Masked Language Model (MLM): 15% of the words in each input sequence are masked (replaced with a [MASK] token), and the model attempts to predict original value of each masked word.
- Next Sentence Prediction (NSP): Data are input as sentence pairs, separated by a [SEP] token. 50% of pairs are randomized, 50% are in their original sequence. The model attempts to predict whether the second sentence IsNext or NotNext. The NSP component of the loss allows BERT to be more generalizable to tasks like Question Answering and Natural Language Inference.
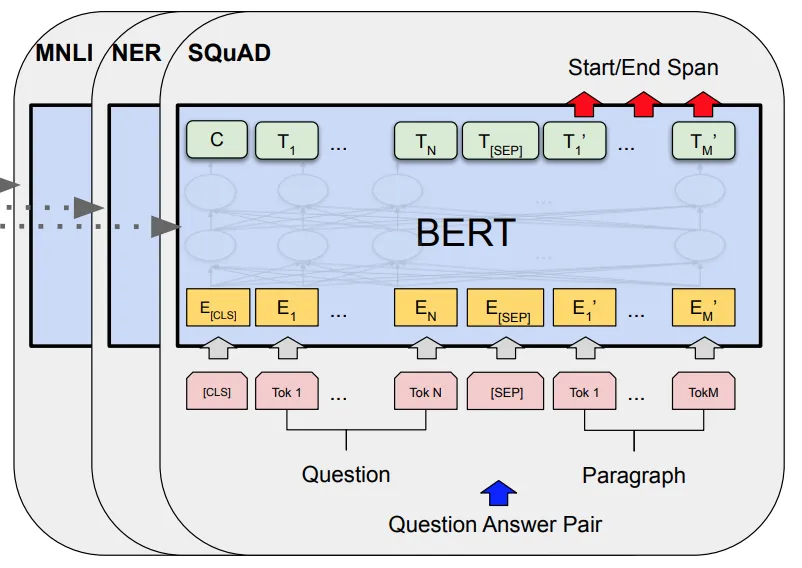
Supervised Fine Tuning
Fine-tuning with BERT is straightforward. It uses labelled data, and for each language model task, we simply plug in the task specific inputs and labels into BERT and fine tune all the parameters.
Performance
BERT shows performance improvements over the state of the art for 11 natural language tasks, and drastically reduces training time for transfer-learning models by requiring only hyper-parameter tuning for many NLP tasks. It is the first fine-tuning based representation model that achieves state-of-the-art performance on a large suite of sentence-level and token-level tasks, outperforming many task-specific architectures.

The importance of its key innovation, bidirectional self-attention, is demonstrated in the ablation study below: it shows that BERTbase outperforms other architectures on different NLU tasks.
-only model")
Conclusion
In this article we discuss Google's BERT which uses bi-directonal self-attention to achieve state of the art on many NLU tasks in 2018. In fact, their innovation has been the basis of many techniques that have achieved the best results since then.
References
Devlin, et al. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv:1810.04805v2.